
Because of code confidentiality, this page only demonstrates the framework
Database Query Language: SimpleQL
A relational database is the most common means of data storage and retrieval in the modern age. A relational database model stores data into one or more tables, where each table has columns and rows. The columns represent a value that can be attributed to an entry (such as color, name, or ID) and the rows represent individual entries or records (such as Name, my_cat, or ABC_1695). For instance, the table pictured below has each row corresponding to a car (a data type), and the columns group a car’s vendors, model, etc. such that this information can be easily retrieved.
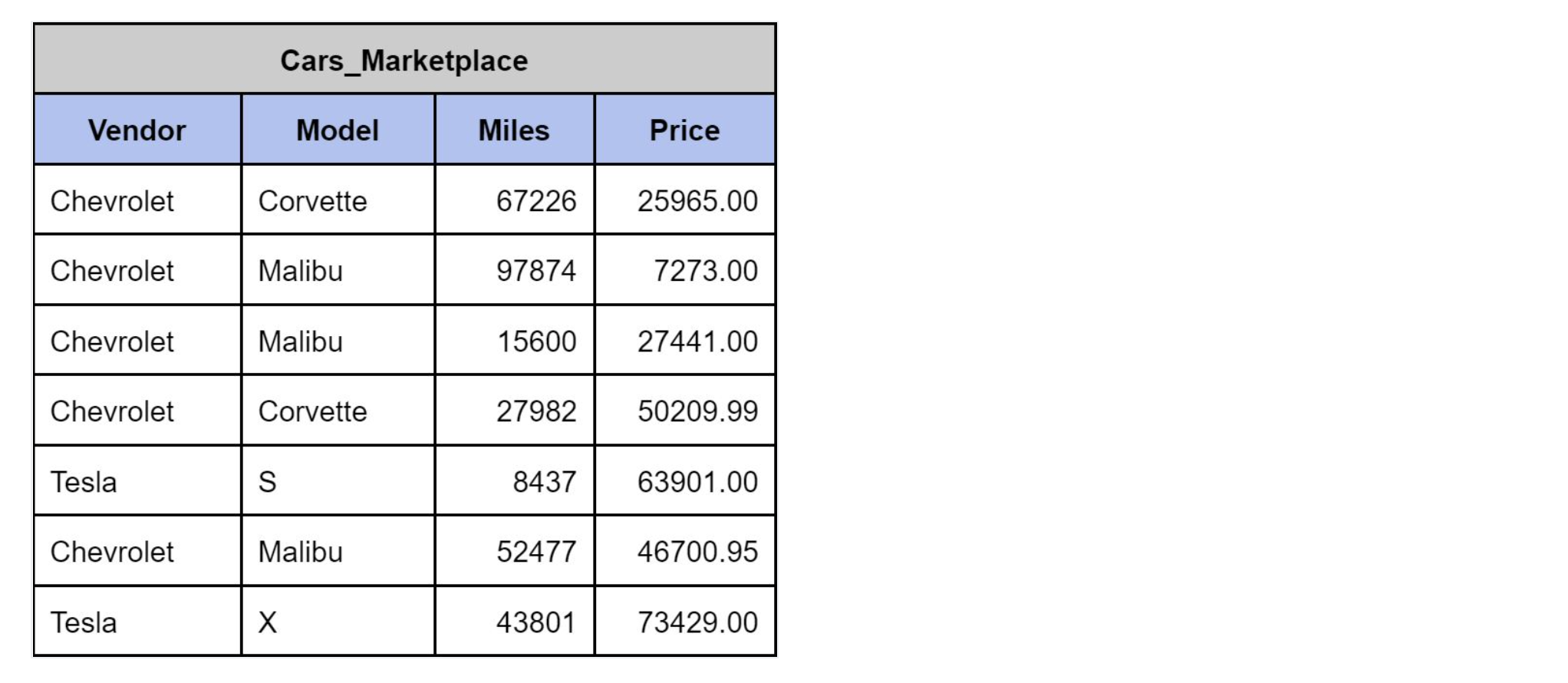
However, a database can do much more than simply store information. You must be able to retrieve specific information in an efficient manner. For relational databases, the structured query language (SQL) is a defined method of retrieving information programmatically. It looks like real English, where a valid command for the above table could be:
SELECT Model from Cars marketplace where Price < 30000
which would return a list of models:
[Corvette, Corvette, Malibu, Malibu, Malibu]
Darabase Commands
These commands affect the structure of the database and the running of the command shell. They include the creation and removal of tables, but do not deal with any actual data (items of type string, double, int or bool).
CREATE
Add a new table to the database:
CREATE Syntax
CREATE <tablename> <N> <coltype1> <coltype2> ... <coltypeN> <colname1> <colname2> ... <colnameN>Creates a new table with N columns (where N > 0). Each column contains data of type [coltype] and is accessed with the name [coltype]. Table names and column names should be guaranteed to be space-free. No two columns in the same table can have the same name (you do not need to check). Valid data types for coltype are {double, int, bool, string}. This table is initially empty.
CREATE Output
Print the following on a single line followed by a newline:
New table <tablename> with column(s) <colname1> <colname2> ... <colnameN> createdQUIT
Exit the program and delete all data in the database.
QUIT Syntax
QUIT
Cleans up all internal data (i.e. no memory leaks) and exits the program. The program exits with a return 0 from main().
QUIT Output
Print a goodbye message, followed by a newline.
Thanks for being simple!
REMOVE
Remove existing table from the database, deleting all data in the table and its definition.
REMOVE Syntax
REMOVE <tablename>Removes the table specified by [tablename] and all associated data from the database, including any created index.
REMOVE Output
Print a confirmation of table deletion, followed by a newline, as follows:
Table <tablename> deletedTable Commands
These commands work on one or more tables and are responsible for interacting with actual data, including insertion, deletion, printing, and indexing.
INSERT
Insert new rows at the end (append) of the specified table.
INSERT Syntax
INSERT INTO <tablename> <N> ROWS
<value11> <value12> ... <value1M>
<value21> <value22> ... <value2M>
...
<valueN1> <valueN2> ... <valueNM>Inserts N new rows into the table specified by tablename. The first line of the command specifies the tablename and the number of rows, N > 0, to be inserted. The next N lines specify the values to be inserted into the table. Each line contains M values, where M is guaranteed to be equal to the number of columns in the table. The first value, [value11], should be inserted into the first column of the table in the first inserted row, the second value, [value12], into the second column of the table in the first inserted row, and so on. Additionally, the types of the values are guaranteed to be the same as the types of the columns they are inserted into. For example, if the second column of the table contains integers, [value12] is guaranteed to be an int. Further, string items are guaranteed to be a single string of whitespace delimited characters (i.e. foo bar is invalid, but foo_bar is acceptable).
INSERT Output
Print the message shown below, followed by a newline, where N is the number of rows inserted, [startN] is the index of the first row added in the table, and [endN] is the index of the last row added to the table, 0 based. So, if there were K rows in the table prior to insertion, [startN] = K, and [endN] = K + N - 1.
Added <N> rows to <tablename> from position <startN> to <endN>Print values from selected columns, in the given order, from specified rows.
PRINT Syntax
PRINT FROM <tablename> <N> <print_colname1> <print_colname2> ... <print_colnameN> {WHERE <colname> <OP> <value> | ALL}Directs the program to print the columns specified by [print_colname1], [print_colname2], … [print_colnameN] from some/all rows in [tablename]. If there is no condition, the command is of the form PRINT ... ALL, and the matching columns from all rows of the table are printed strictly in insertion order. If there is a condition, the command is of the form PRINT ... WHERE [colname] [OP] [value], and only rows whose values in the selected [colname] pass the condition are printed. The rules for the conditional portion are the same as for the DELETE command. The number and order of the column names given in the command do not have to match the number or order of columns in the specified table.
If no index exists or there is a hash index on the conditional column, the results should be printed in order of insertion into the table.
If a bst index exists on the conditional column, the results should be printed in the order in the BST (least item to greatest item for std::map constructed with the default std::less operator), with ties broken by order of insertion into the table.
PRINT Output
Print the requested data followed by a summary. Printing the data is accomplished by printing a single line with the names of the selected columns, followed by a single line from each specified row, where the values of each of the selected columns are separated by a single space. Every line should be followed by a newline.
<print_colname2> ... <print_colnameN>
<value2row1> ... <valueNrow1>
...
<value2rowM> ... <valueNrowM>To print the summary, on a single line, print the number of rows M printed, and the [tablename] from which the rows were printed, followed by a newline.
Printed <M> matching rows from <tablename>DELETE
Delete selected rows from the specified table.
DELETE Syntax
DELETE FROM <tablename> WHERE <colname> <OP> <value>Deletes all rows from the table specified by [tablename] where the value of the entry in [colname] satisfies the operation [OP] with the given value [value]. You can assume that [value] will always be of the same type as [colname]. For example, to delete all rows from table1 where the entries in column name equal John, the command would be:
DELETE FROM table1 WHERE name = JohnOr, to delete all rows from tableSmall where the entries in column size are greater than 15, the command would be:
DELETE FROM tableSmall WHERE size > 15[OP] can be from the set {<, >, =}.
DELETE Output
Print a summary of the number of rows deleted from the table as shown below, followed by a newline:
Deleted <N> rows from <tablename>JOIN
Join two tables where values in selected columns match, and print results.
JOIN Syntax
JOIN <tablename1> AND <tablename2> WHERE <colname1> = <colname2> AND PRINT <N> <print_colname1> <1|2> <print_colname2> <1|2> ... <print_colnameN> <1|2>Directs the program to print the data in N columns, selected by [print_colname1], [print_colname2], … [print_colnameN]. The [print_colname]s will be the names of columns in either the first table [tablename1] or the second table [tablename2], as chosen by the 1/2 argument directly following each </code>[print_colname]</code>.
JOIN Output
Print the requested data followed by a summary. Printing the data is accomplished by printing a single line with the names of the selected columns, followed by a single line from each joined row, where the values of each of the selected columns are separated by a single space. Every line should be followed by a newline.
<print_colname1> <print_colname2> ... <print_colnameN>
<value1rowA> <value2rowA> ... <valueNrowA>
...
<value1rowM> <value2rowM> ... <valueNrowM>
To print the summary, on a single line, print the number of rows N printed, and both [tablename1] and [tablename2] which were joined, followed by a newline.
Printed <N> rows from joining <tablename1> to <tablename2>
GENERATE
Create a search index on the selected column in the specified table.
GENERATE Syntax
GENERATE FOR <tablename> <indextype> INDEX ON <colname>Directs the program to create an index of the type [indextype] on the column [colname] in the table [tablename], where [indextype] is limited to the set {hash, bst}, denoting a hash table index and a binary search tree index respectively. Given the [indextype] hash on column [colname], the program should create a hash table that allows a row in the table to be found rapidly given a particular value in the column [colnam]. Given the [indextype] bst on column [colname], the program should create a binary search tree that allows rows in the table to be found rapidly given a particular value in the column [colname]. Only one user-generated Index may exist per table, at any one time. If a valid index is requested on a table that already has one, discard the old index before building the new one.
When bst is the specified index type, a std::map should be applied; when hash is the specified index type, a std::unordered_map should be utilized. It is acceptable for both types to exist at the same time, but only one should be in use or contain data at any given time.